
Engineering Best Practices for Data Science Teams

Data science is a dynamic field that relies on the intersection of statistics, machine learning, and engineering. To ensure the success of data science projects, it's essential to establish robust engineering best practices. In this article, we will explore some key principles and strategies that can help data science teams improve their engineering workflows and deliver more effective solutions.
This article is dedicated to all of my data science teams and cross-functional software engineering / business intelligence collaborators with whom I have had the privilege of working. I firmly believe that these individuals are the true giants upon whose shoulders we stand: The builders!

Version Control and Collaboration
One of the fundamental practices for any engineering team, including data science, is version control. Tools like Git enable data scientists to track changes in their code and collaborate seamlessly with team members. Here's how data science teams can leverage version control:
Use Git: Employ Git for version control, and host your code on platforms like GitHub or GitLab. This allows for easy collaboration and code sharing within your team.
Branching Strategy: Develop a clear branching strategy that separates feature development, bug fixes, and production releases. This ensures that code changes are organized and well-documented.
Code Reviews: Implement code review processes to maintain code quality and share knowledge among team members.
Don't be afraid of branching & pull requests

Reproducibility and Documentation
Data science projects often involve complex data preprocessing, modeling, and analysis. To ensure reproducibility and transparency, documentation is crucial:
Jupyter Notebooks: Use Jupyter Notebooks or similar tools for documenting your analysis. Include clear explanations of your methods, assumptions, and results.
Version Your Data: Versioning your datasets is as important as versioning your code.
Containerization: Containerize your code using platforms like Docker to ensure that your models and environments are reproducible across different systems.
Document, document, document everything. Use wiki-like platforms like Confluence to share the fundamentals of what your models are doing. Do not forget adding there business assumptions, feature engineering you’ve done etc. (if you personally know me, you know my OCD with Documentation)
If you have a platform for tracking your work and tasks try to have a connection between the namings you use in your work items and the code you are pushing.
Monitoring and Error Handling
In production, monitoring and error handling are critical to ensure the reliability of your data science applications:
Logging: Implement robust logging to record important events and errors in your application.
Monitoring Tools: Use monitoring tools like Prometheus and Grafana to track the performance and health of your data pipelines and models.
Alerts: Configure alerts to notify your team of issues that require immediate attention, such as model degradation or data pipeline failures.
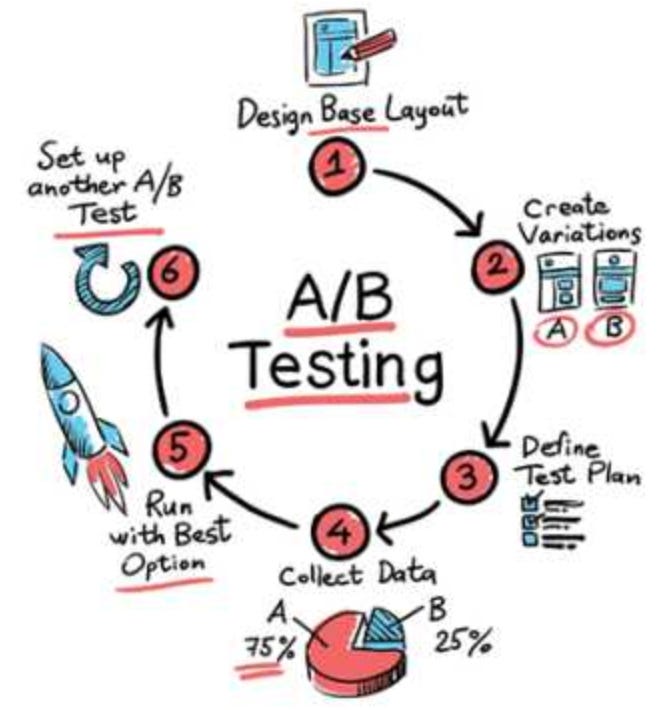
A/B Testing
Implement A/B testing to evaluate the impact of model changes and make informed decisions.
Engineering best practices are vital for the success of data science teams. By adopting version control, documentation, automated testing, monitoring, and deployment strategies, data scientists can work more efficiently, reduce errors, and deliver more reliable and scalable solutions. These practices enable data science teams to bridge the gap between research and production, ultimately driving more value from their data-driven insights.
References
Management of Machine Learning Lifecycle Artifacts: A Survey, by Marius Schlegel and Kai-Uwe Sattler
The Art and Practice of Data Science Pipelines: A Comprehensive Study of Data Science Pipelines in Theory, in-the-Small, and in-the-Large by Biswas, Sumon and Wardat, Mohammad and Rajan, Hridesh