


AI Bias, Toxicity, Hallucination: 3 concerning phenomena and mitigation proposals

As AI continues to advance, researchers and experts are increasingly concerned about several phenomena that have emerged in recent years. These include AI hallucination, bias, and toxicity, all of which have the potential to cause harm to individuals and society. In this article, we will explore each of these phenomena in detail, examining their causes, potential consequences, mitigation proposals, and the scientific research behind them. It is important to address these concerns as we continue to develop and implement AI technology, in order to ensure that it is safe, ethical, and beneficial to humanity.
The concept of training datasets
Training is a critical step in developing artificial intelligence and machine learning models that can effectively learn from data and make accurate predictions. However, without proper oversight and care during the training process, these models can develop undesirable behaviors.

Conventional Machine Learning Training
In Machine Learning, the ML model is initially fit on a training data set, which is a set of examples used to fit the parameters (e.g., weights of connections between neurons in artificial neural networks) of the model. The model (e.g., a naive Bayes classifier) is trained on the training data set using a supervised learning method, for example using optimization methods such as gradient descent or stochastic gradient descent. In practice, the training data set often consists of pairs of an input vector (or scalar) and the corresponding output vector (or scalar), where the answer key is commonly denoted as the target (or label). The current model is run with the training data set and produces a result, which is then compared with the target, for each input vector in the training data set. Based on the result of the comparison and the specific learning algorithm being used, the parameters of the model are adjusted. The model fitting can include both variable selection and parameter estimation. Successively, the fitted model is used to predict the responses for the observations in a second data set called the validation data set.
The validation data set provides an unbiased evaluation of a model fit on the training data set while tuning the model's hyperparameters (e.g., the number of hidden units—layers and layer widths—in a neural network). Validation datasets can be used for regularization by early stopping (stopping training when the error on the validation data set increases, as this is a sign of over-fitting to the training data set). This simple procedure is complicated in practice by the fact that the validation dataset's error may fluctuate during training, producing multiple local minima. This complication has led to the creation of many ad-hoc rules for deciding when over-fitting has truly begun.
Finally, the test data set is a data set used to provide an unbiased evaluation of a final model fit on the training data set. If the data in the test data set has never been used in training (for example in cross-validation), the test data set is also called a holdout data set. The term "validation set" is sometimes used instead of "test set" in some literature (e.g., if the original data set was partitioned into only two subsets, the test set might be referred to as the validation set).

In-context learning in AI
In-context learning was popularized in the original GPT-3 paper as a way to use language models to learn tasks given only a few examples. During in-context learning, we give the LM a prompt that consists of a list of input-output pairs that demonstrate a task. At the end of the prompt, we append a test input and allow the LM to make a prediction just by conditioning on the prompt and predicting the next tokens. To correctly answer the two prompts below, the model needs to read the training examples to figure out the input distribution (financial or general news), output distribution (Positive/Negative or topic), input-output mapping (sentiment or topic classification), and the formatting.

What can in-context learning do? On many benchmark NLP benchmarks, in-context learning is competitive with models trained with much more labeled data and is state-of-the-art on LAMBADA (commonsense sentence completion) and TriviaQA (question answering). Perhaps even more exciting is the array of applications that in-context learning has enabled people to spin up in just a few hours, including writing code from natural language descriptions, helping with app design mockups, and generalizing spreadsheet functions.
Why is in-context learning surprising? In-context learning is unlike conventional machine learning in that there’s no optimization of any parameters. However, this isn’t unique—meta-learning methods have trained models that learn from examples . The mystery is that the LM isn’t trained to learn from examples. Because of this, there’s seemingly a mismatch between pretraining (what it’s trained to do, which is next token prediction) and in-context learning (what we’re asking it to do).
How does the LM learn to do Bayesian inference during pretraining?
An LM trained (using next token prediction) with a latent concept structure can learn to do in-context learning. The document-level latent concept creates long-term coherence, and modeling this coherence during pretraining requires learning to infer the latent concept:
Pretrain: To predict the next token during pretraining, the LM must infer (“locate”) the latent concept for the document using evidence from the previous sentences.
In-context learning: If the LM also infers the prompt concept (the latent concept shared by examples in the prompt) using in-context examples in the prompt, then in-context learning occurs.
LLMs like GPT-3 have been trained on a massive amount of text with a wide array of topics and formats, from Wikipedia pages, academic papers, and Reddit posts to Shakespeare’s works. Training on this text allows the LM to model a diverse set of learned concepts.
What’s a concept? We can think of a concept as a latent variable that contains various document-level statistics. For example, a “news topics” concept describes a distribution of words (news and their topics), a format (the way that news articles are written), a relation between news and topics, and other semantic and syntactic relationships between words. In general, concepts may be a combination of many latent variables that specify different aspects of the semantics and syntax of a document.

The power (and responsibility) lies in the original training data and the assigned (or inferred) context
One of the biggest trends in natural language processing (NLP) has been the increasing size of language models (LMs) as measured by the number of parameters and size of training data. While investigating properties of LMs and how they change with size holds scientific interest, and large LMs have shown improvements on various tasks, we ask whether enough thought has been put into the potential risks associated with developing them and strategies to mitigate these risks.
The tendency of human interlocutors to impute meaning where there is none can mislead both NLP researchers and the general public into taking synthetic text as meaningful. Combined with the ability of LMs to pick up on both subtle biases and overtly abusive language patterns in training data, this leads to risks of harms, including encountering derogatory language and experiencing discrimination at the hands of others who reproduce racist, sexist, ableist, extremist or other harmful ideologies reinforced through interactions with synthetic language.
Size Doesn’t Guarantee Diversity
Large language models may act as stochastic parrots, repeating potentially dangerous text.
The Internet is a large and diverse virtual space, and accordingly, it is easy to imagine that very large datasets, such as Common Crawl (“petabytes of data collected over 8 years of web crawling”, a filtered version of which is included in the GPT-3 training data) must therefore be broadly representative of the ways in which different people view the world.
However, on closer examination, we find that there are several factors which narrow Internet participation, the discussions which will be included via the crawling methodology, and finally the texts likely to be contained after the crawled data are filtered. In all cases, the voices of people most likely to hew to a hegemonic viewpoint are also more likely to be retained.
Starting with who is contributing to these Internet text collections, we see that Internet access itself is not evenly distributed, resulting in Internet data overrepresenting younger users and those from developed countries. However, it’s not just the Internet as a whole that is in question, but rather specific subsamples of it. For instance, GPT-2’s training data is sourced by scraping outbound links from Reddit, and Pew Internet Research’s 2016 survey reveals 67% of Reddit users in the United States are men, and 64% between ages 18 and 29. Similarly, recent surveys of Wikipedians find that only 8.8–15% are women or girls.
Risks and Harms by Bias and Toxicity LM Phenomena
The first risks we consider are the risks that follow from the LMs absorbing the hegemonic worldview from their training data. When humans produce language, our utterances reflect our worldviews, including our biases. As people in positions of privilege with respect to a society’s racism, misogyny, ableism, etc., tend to be overrepresented in training data for LMs, this training data thus includes encoded biases, many already recognized as harmful.
Biases can be encoded in ways that form a continuum from subtle patterns like referring to women doctors as if doctor itself entails not-woman or referring to both genders excluding the possibility of non-binary gender identities, through directly contested framings (e.g. undocumented immigrants vs. illegal immigrants or illegals), to language that is widely recognized to be derogatory (e.g. racial slurs) yet still used by some. While some of the most overtly derogatory words could be filtered out, not all forms of online abuse are easily detectable using such taboo words, as evidenced by the growing body of research on online abuse detection. Furthermore, in addition to abusive language and hate speech, there are subtler forms of negativity such as gender bias, microaggressions, dehumanization, and various socio-political framing biases that are prevalent in language data.

Readers subject to the stereotypes may experience the psychological harms of microaggressions and stereotype threat. Other examples of issues include: propagating or proliferating overtly abusive views and associations, amplifying abusive language, and producing more (synthetic) abusive language that may be included in the next iteration of large-scale training data collection. The harms that could follow from these risks are again similar to those identified above for more subtly biased language, but perhaps more acute to the extent that the language in question is overtly violent or defamatory.
If the LM or word embeddings derived from it are used as components in a text classification system, these biases can lead to allocational and/or reputational harms, as biases in the representations affect system decisions. This case is especially pernicious for being largely invisible to both the direct user of the system and any indirect stakeholders about whom decisions are being made.
Similarly, biases in an LM used in query expansion could influence search results, further exacerbating the risk of harm where the juxtaposition of search queries and search results, when connected by negative stereotypes, reinforce those stereotypes and cause psychological harm. The above cases involve risks that could arise when LMs are deployed without malicious intent.
Another category of risk involves bad actors taking advantage of the ability of large LMs to produce large quantities of seemingly coherent texts on specific topics on demand in cases where those deploying the LM have no investment in the truth of the generated text. These include prosaic cases, such as services set up to ‘automatically’ write term papers or interact on social media, as well as use cases connected to promoting extremism.
Are there ways of mitigating Bias and Toxicity?
There are several efforts from research organizations and companies for mitigating bias and toxicity in AI. Here are a few examples:
FairSeq: FairSeq is an open-source toolkit developed by Facebook AI Research for training and evaluating sequence-to-sequence models, which are commonly used in machine translation, summarization, and other natural language processing tasks. It includes several methods for mitigating bias and toxicity, such as adversarial training and debiasing techniques.
OpenAI's GPT-3: OpenAI, the company behind the GPT-3 LLM, has implemented several strategies to mitigate bias and toxicity in the model. For example, they have fine-tuned the model on a dataset of non-toxic text, and they have implemented a content filter that prevents the model from generating text that is explicitly toxic or harmful.
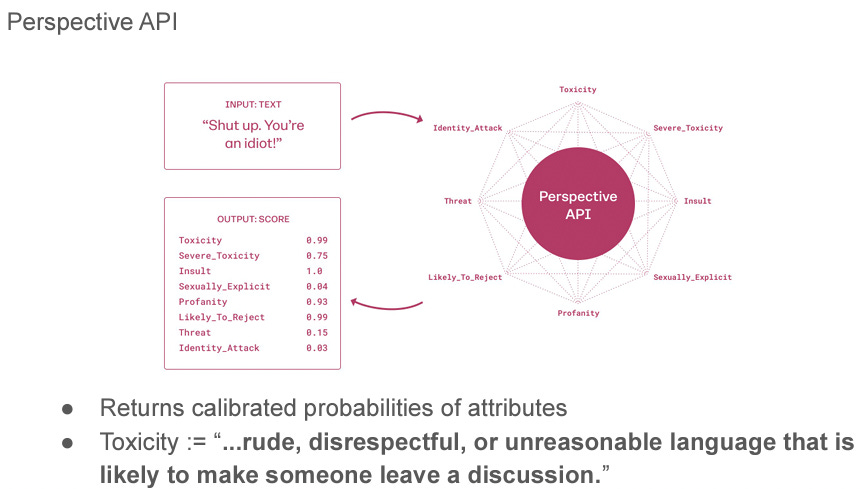
Perspective API: Perspective API is a machine learning tool developed by Jigsaw, a subsidiary of Google's parent company Alphabet. It is designed to identify and flag online comments and content that may contain toxic or harmful language. The API uses natural language processing algorithms to analyze text and detect patterns of abusive or harassing behavior, allowing moderators and administrators to take action to protect users and maintain a safe online environment. The tool has been integrated into various platforms and websites, including Wikipedia, The New York Times, and The Guardian, to help combat online harassment and improve the overall quality of online discourse.
Hugging Face's Transformers: Hugging Face is a company that develops and maintains a popular open-source library of pre-trained LLMs called Transformers. They have implemented several strategies for mitigating bias and toxicity in their models, including fine-tuning on non-toxic datasets and implementing content filters.
Fighting the Ghosts in the (Shell : ) ) Machine: Addressing Hallucination in LLMs and Generative AI
Hallucination is the production of content that is not based on any factual or semantic evidence. In the context of LLMs, it refers to the generation of text that is not coherent or logical, often leading to the production of nonsensical or contradictory statements. This phenomenon is a significant challenge for LLMs, as it can significantly affect the quality and reliability of their output.
The causes of hallucination in LLMs are complex and multifaceted. One major cause is the bias in the training data. LLMs are typically trained on massive amounts of data, and if this data contains biased or incomplete information, the model may learn incorrect or incomplete facts. This can lead to the generation of text that is inconsistent or incoherent. Another cause of hallucination is the lack of context. LLMs do not have a complete understanding of the world, and their output is based solely on the input they receive. This means that if the input is incomplete or ambiguous, the model may fill in the gaps with incorrect or irrelevant information.
Hallucination is not unique to LLMs and can also occur in other forms of generative AI. One example is image generation, where a generative model may produce an image that is not based on any real-world object or scene. Another example is speech generation, where a generative model may produce speech that is not coherent or intelligible. In these cases, the causes and solutions to hallucination are similar to those for LLMs.

Breaking the Illusion
Several potential solutions have been proposed to address the problem of hallucination in LLMs. One approach is to improve the quality of the training data by removing biased or incomplete information. Another solution is to provide the model with more context. This can be achieved by integrating external knowledge sources or by training the model on a broader range of topics. Another solution is to introduce constraints on the output generated by the model. For example, researchers can limit the vocabulary or structure of the generated text to ensure that it is more coherent and logical.
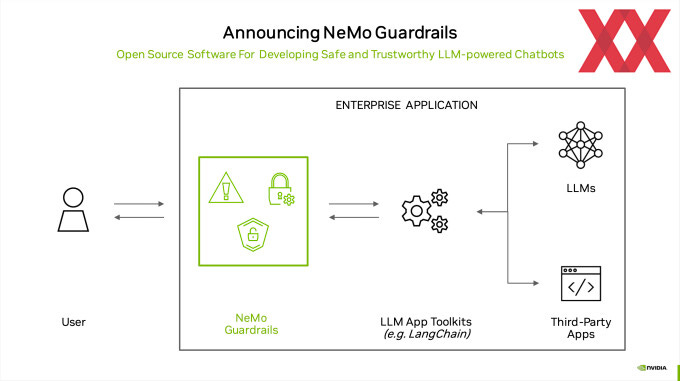
Recently, Nvidia announced new software that will help software makers prevent AI models from saying incorrect facts, talking about harmful subjects, or opening up security holes. The software, called NeMo Guardrails, is one example of how the AI industry is right now scrambling to address the hallucination issue.
From Concerns to Solutions
Despite the concerns surrounding AI bias, toxicity, and hallucination, the AI research community is making significant strides towards developing more ethical and reliable AI systems. Researchers are exploring a range of solutions to address these issues, including improved data collection and curation, the use of explainable AI techniques, and the development of more robust algorithms that can better detect and mitigate bias.
Moreover, there is growing recognition that addressing these challenges is not just a technical problem, but a social and ethical one as well. As a result, there is increasing collaboration between AI researchers, policymakers, and community stakeholders to ensure that AI is developed in a way that benefits society as a whole.
While there is still much work to be done, these efforts give cause for optimism that AI can be harnessed to improve our lives and tackle some of the most pressing challenges facing humanity. By working together to mitigate AI bias, toxicity, and hallucination, we can create AI systems that are more trustworthy, reliable, and equitable, and that can help us solve some of the world's most complex problems.
Recommended references and resources for AI Bias, Toxicity, Hallucination and respective Solutions
https://www.cs.princeton.edu/courses/archive/fall22/cos597G/
https://www.cs.princeton.edu/courses/archive/fall22/cos597G/lectures/lec01.pdf
https://www.cs.princeton.edu/courses/archive/fall22/cos597G/lectures/lec14.pdf
https://www.cs.princeton.edu/courses/archive/fall22/cos597G/lectures/lec15.pdf
https://hai.stanford.edu/news/who-decides-dealing-online-toxic-speech-selecting-decision-makers
https://en.wikipedia.org/wiki/Hallucination_(artificial_intelligence)
https://chat.openai.com/
helped me edit the article